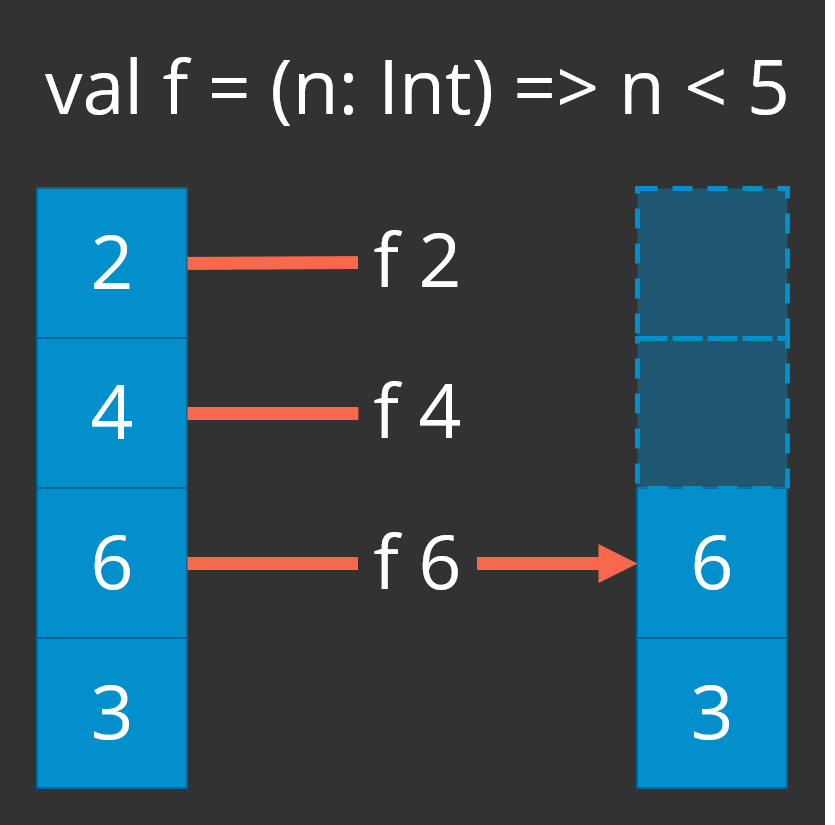Filtering over a sequence of values omits values that do not meet certain criteria. Mapping over a sequence of values transforms each value into another value. What if you could do both at the same time—filter out unwanted values, but transform the ones that are left? You can with Stream.collect. But first, you need to know about partial functions.
Partial Functions
A partial function is a function that has a limited domain, i.e., is not defined for every possible value of its input type, but only a subset.
The classic example is division. Division is undefined for a divisor of zero. In other words, m ÷ n is valid unless n = 0. So then, division is not defined for every number n. In this particular example, that’s not a big limitation on the domain, but it is nevertheless a limitation that prevents us from saying that division is defined for every possible n.
Scala has a PartialFunction type that allows you to represent a function that is only valid for a limited domain. Here is how you could represent integer division:
val divide = new PartialFunction[(Int,Int), Int] {
override def isDefinedAt(x: (Int, Int)) = x._2 != 0
override def apply(x: (Int, Int)) = x._1 / x._2
}
val quotient = divide(12, 4)
// quotient: Int = 3
Partial functions have the apply method that other functions have so that you can execute them with parentheses: divide(12, 3). They also have an isDefinedAt method so that you can ask the partial function, “Hey, can you handle this input?” That way, you can use an if-else expression to return a default or some other value:
val fine = if (divide.isDefinedAt(12, 4)) {
divide(12, 4)
} else Int.MaxValue
// three: Int = 3
val meh = if (divide.isDefinedAt(12, 0)) {
divide(12, 0)
} else Int.MaxValue
// meh: Int = 2147483647
In fact, this is such a common pattern, that PartialFunction has applyOrElse that takes an input and a default function that is executed if the partial function is not defined for the given input:
val default = Function.const(Int.MinValue) _ // lifted val fine = divide.applyOrElse((12, 4), default) // fine: Int = 3 val meh = divide.applyOrElse((12, 0), default) // meh: Int = -2147483648
Now just because a partial function has a limited domain doesn’t mean that Scala prevents you from calling it on inputs that are outside its domain:
val quotient = divide(12, 0) // java.lang.ArithmeticException: / by zero
Therefore, remember to check the domain of a partial function before applying it to a given input. A responsibly crafted API that accepts partial functions from you will verify that an input is in the partial function’s domain before applying it.
You may be thinking, “That’s great, but it’s got a lot of boilerplate.” That’s true. Scala is nice enough to let you use pattern matching syntax to define a partial function in a terser fashion:
val divide: PartialFunction[(Int,Int), Int] = {
case (num, den) if den != 0 => num / den
}
val quotient = divide(12, 4)
// quotient: Int = 3
Finally, perhaps a single partial function is not defined for the entire set of possible inputs, but you can use multiple partial functions that together cover the entire input range. It’s a contrived example, but you can take one partial function that is defined for even integers and another one that is defined for odds and then compose them together with the orElse method to get a partial function that does cover the entire set of possible inputs:
val square: PartialFunction[Int,Int] = {
case x if x % 2 == 0 => x * x
}
val cube: PartialFunction[Int,Int] = {
case x if x % 2 == 1 => x * x * x
}
val transform = square orElse cube
val squared = transform(4)
// squared: Int = 16
val cubed = transform(3)
// cubed: Int = 27
Collect: Filter and Map in One
Whereas Stream.filter takes a predicate—a function that takes a value and returns a Boolean—Stream.collect takes—you guessed it—a partial function. Stream.collect checks each element of the stream to see whether it is in the partial function’s domain. If the partial function is not defined for the input element, then Stream.collect discards it. If the input is within the partial function’s domain, then Stream.collect applies the partial function to the input element and returns the result as the next element in the output sequence.
val squaredEvens = (4 to 7).toStream.collect {
case n if n % 2 == 0 => n * n
}
// squaredEvens: Stream[Int] = Stream(16, 36)
The following graphic illustrates what is going on in the code above:

OK, so Stream.collect performs a filter and a map all in one. Why not just call Stream.filter and then Stream.map? One example I’ve seen is when you’re pattern matching and destructuring and then only using one/some of the potential match cases. Perhaps you have a trait and some case classes representing orders that were either fulfilled or cancelled before fulfillment:
trait Order case class Fulfilled(id: String, total: BigDecimal) case class Cancelled(id: String, total: BigDecimal)
You’d like to know how many dollars you “lost” in cancelled orders. Use Stream.collect to extract the dollar value of each cancelled order, and then sum them:
val orders = Stream(
Fulfilled("fef3356074b4", BigDecimal("28.50")),
Fulfilled("2605c9988f1d", BigDecimal("88.25")),
Cancelled("94edac47971f", BigDecimal("22.01")),
Fulfilled("2a1ff57b8f46", BigDecimal("39.30")),
Fulfilled("9ee0a3e3da3a", BigDecimal("27.97")),
Cancelled("db5dc439ad93", BigDecimal("99.49")),
Fulfilled("08d58811ed36", BigDecimal("53.72")),
Cancelled("63ebd07475ca", BigDecimal("93.66")),
Cancelled("12d16ae9c112", BigDecimal( "7.79")),
Fulfilled("c5ecedaedb0e", BigDecimal("87.21")) )
val cancelledDollars = orders.collect {
case Cancelled(_, dollars) => dollars
}.sum
// cancelledDollars: BigDecimal = 222.95